变量基础
什么是变量?
想象一下,你在搭建一个复杂的乐高模型,每个模块都需要精确地连接在一起。在工作流(Workflow)的世界里,变量就扮演着类似“连接件”的角色。它们是用来在不同节点之间传递信息的“信使”。
简单来说,变量就是一个带名字的容器,你可以往里面装各种东西,比如用户的输入、计算结果,或者从某个地方获取的数据。
一个变量通常由三部分组成:
- 名字(唯一标识符):就像你的名字一样,它让大家能准确地找到这个变量。例如
userName、orderId。 - 值:容器里装的东西。它可以是数字
123,文字"Hello Flowgram!",或者一个开关状态true/false。 - 类型:规定了这个容器能装哪种东西。比如,有的只能装数字,有的只能装文字。
举个例子,在一个“智能问答”流程中:
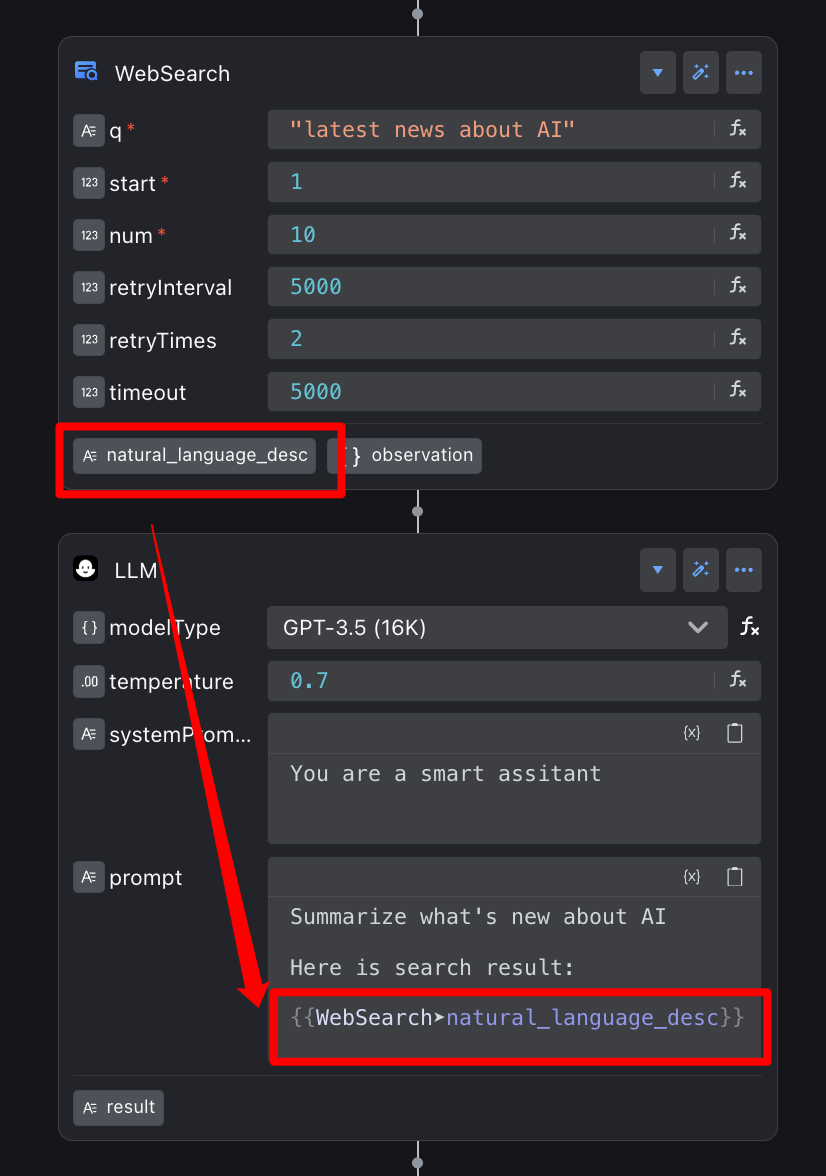
1. WebSearch 节点:负责上网搜索,然后把搜到的知识(比如“今天天气怎么样?”的答案)放进一个名为 natural_language_desc 的变量里。
2. LLM 节点:它会接过 natural_language_desc 这个“信使”,读取里面的内容,然后用更自然、更友好的方式回答用户。
3. 在这个过程中,natural_language_desc 的类型就是“字符串”,因为它装的是文字内容。
为什么需要变量引擎?
随着工作流复杂度的提升,变量的数量和管理难度也随之增加。
为了应对这一挑战,Flowgram 提供了强大的变量引擎。
它如同一位�专业的“数据管家”,能够系统化地管理所有变量,确保数据流的清晰与稳定。
启用变量引擎将为您带来以下核心优势:
变量引擎能够精确控制每个变量的有效范围(即作用域)。如同为不同房间配置专属钥匙,它确保了变量只在预期的节点中被访问,从而有效避免了数据污染和意外的逻辑错误。
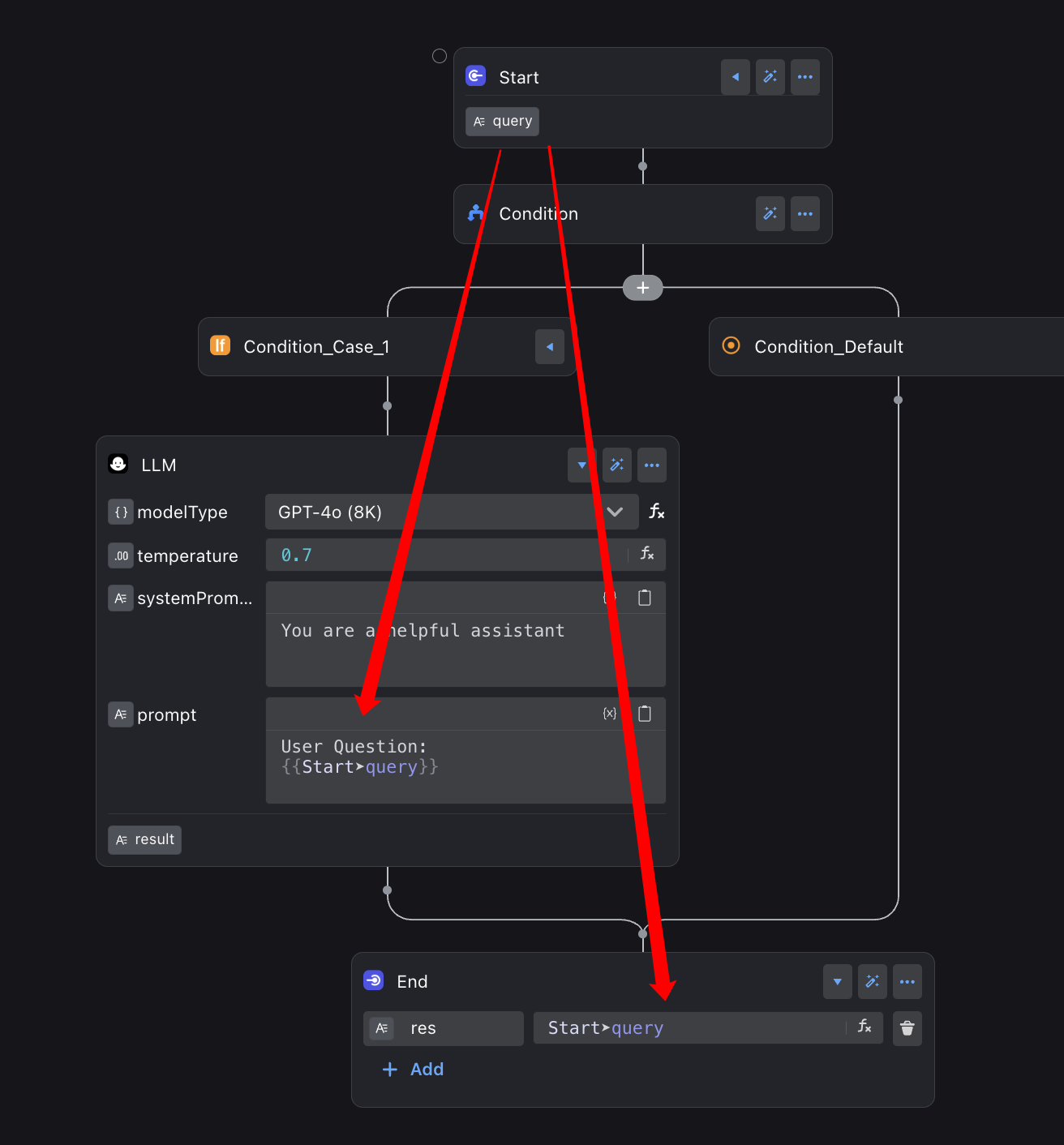
Start 节点定义的 query 变量,在它后面的 LLM 和 End 节点都能轻松访问。
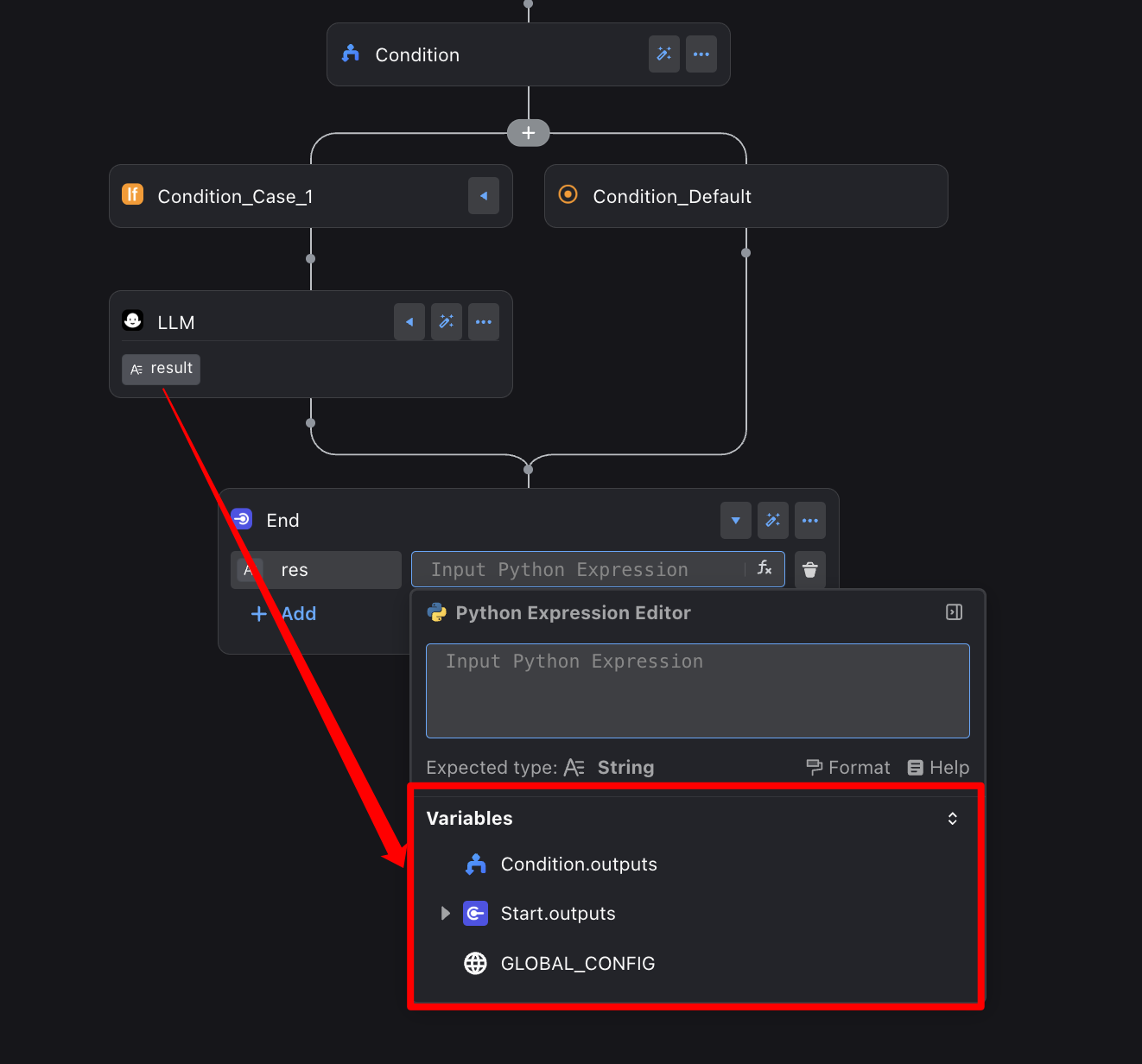
LLM 节点在一个 Condition 分支里,像是在一个独立的房间。外面的 End 节点自然就拿不到它的 result 变量了。
当变量变得复杂时(例如一个包含许多层级的对象),变量引擎能让你像剥洋葱一样,一层层地深入探索它的内部结构,所有细节都尽在掌握。
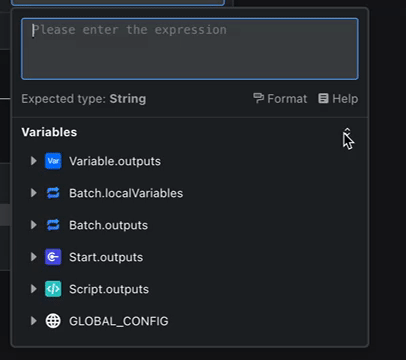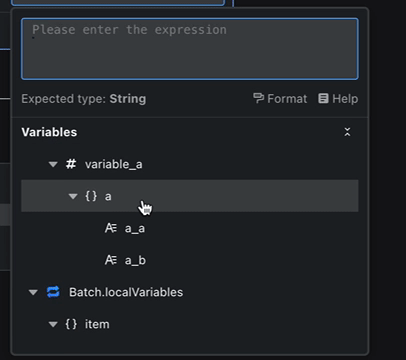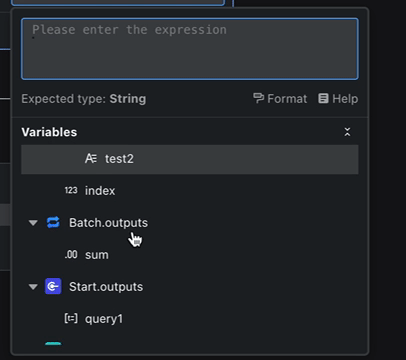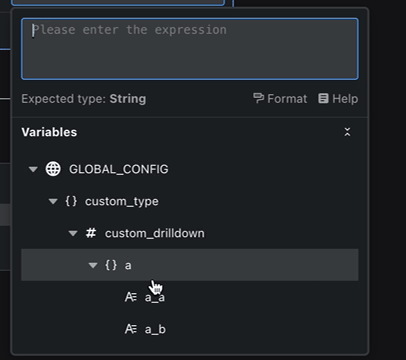
这张图里,你能看到所有节点的输出变量,以及它们之间的层级关系,像一棵枝繁叶茂的树。
你不用再挨个告诉每个变量它应该是什么类型,变量引擎会像你的“灵魂伴侣”一样,根据上下文自动推导出它的类型。
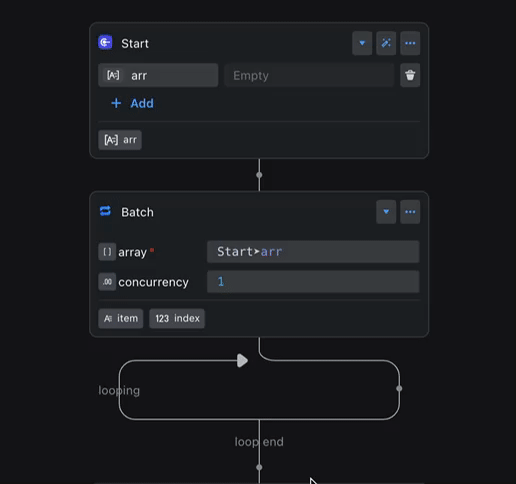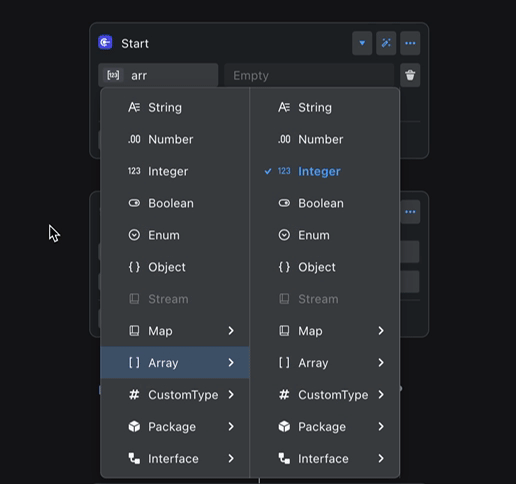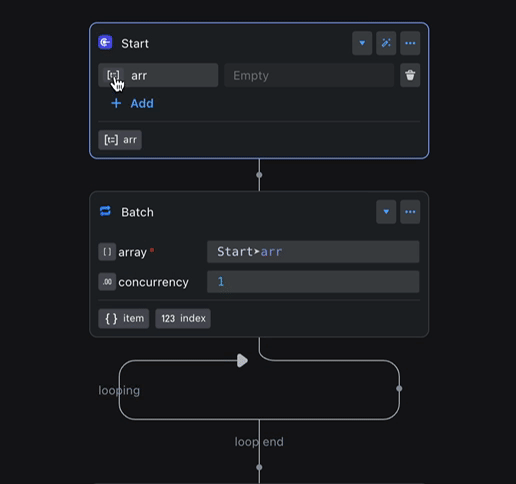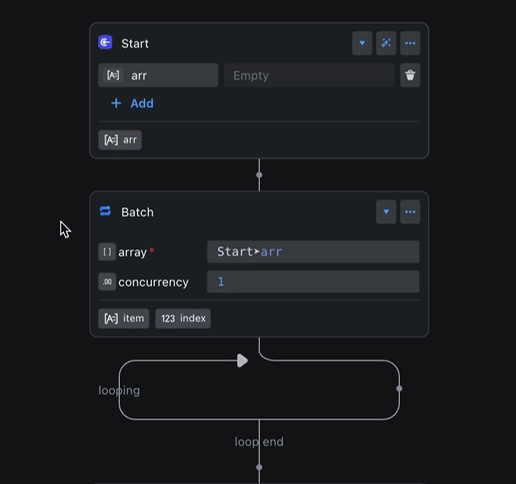
例如,当 Start 节点中 arr 变量的类型发生变更时,Batch 节点输出的 item 类型也会自动同步更新,确保了类型的一致性。
如何开启变量引擎?
您可以通过简单的配置来启用变量引擎,以体验其强大的功能。